
I recently read this paper about Google’s load balancer Maglev. Some unstructured notes -
- serving google’s traffic since 2008
- sits between the internet and google’s services operating at the L4 layer
- uses consistent hashing + a local connection table to route packets
- runs on commodity linux servers, no special physical racks
How it works
- VIP - virtual IP address. Every google service(like search, gmail, calendar etc.) has one or more VIPs. These are different from physical IP as they’re not assigned to a specific network interface, but rather served by multiple service endpoints behind Maglev.
- the maglev machines advertise the service’s VIP(virtual IP address) to the network routers over BGP(Border Gateway Protocol) which are aggregated and announced to the Internet. Network routers then distribute packets to the maglev machines via ECMP(equal cost multipath).
- Maglev then matches those packets to corresponding services and distributes the load evenly to the service endpoints.
- highly performant - a single machine can saturate a 10Gbps connection.
- User facing flow -
- you type google.com in your browser and hit enter
- DNS query goes to google’s authoritative DNS server, which returns a VIP taking into account your location and current load at each location
- browser tries to establish a connection with the VIP
- network router(hardware device) receives VIP packets and forwards to one of the Maglev machines in the DC through ECMP
- Maglev then encapsulates the packet(to change the header destination IP to that of the actual endpoint) using Generic Routing Encapsulation (GRE) and forwards to an endpoint from the set of service endpoints associated with the VIP.
- The service endpoint then decapulates and consumes the packet.
- The response when ready is put into a packet with destination as user’s ip and and source address being the VIP.
- Direct server return is used to send responses directly to the router instead of passing it through the maglev machine(response size is usually larger than the request size). This is a neat trick bypassing maglev in the return path.
Maglev Deployment
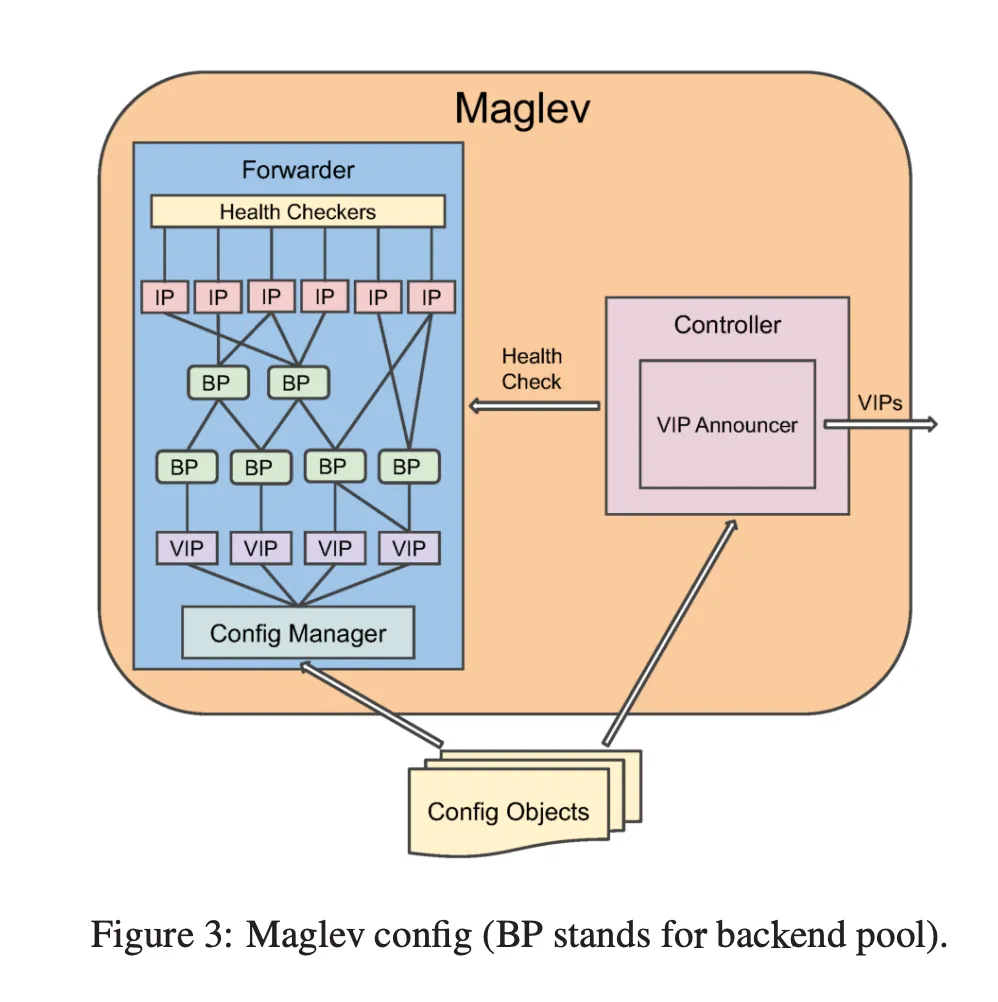
- Maglev cluster is a set of machines on which maglev is running and which are all advertising the same set of VIPs.
- A maglev machine has access to config objects(read from file or received from external systems)
- the config objects have detail about VIPs to be served
- Each VIP is configured with one or more backend pools(BP). A BP can either contain the physical IP address of the service endpoints or recursively contain other BPs.
- There are two parts in maglev service running on a machine -
- Forwarder - has the VIP to BP(backend pools) mapping, responsible for forwarding the packets to the right service endpoint. Periodicaly health checks all the service endpoints configured.
- Controller - Health checks forwarder periodically. responsible for announcing/withdrawing the VIPs to router depending on how the health check goes.
- It’s possible to deploy shards of maglevs in same cluster serving different set of VIPs for performance isolation or testing.
Forwarder
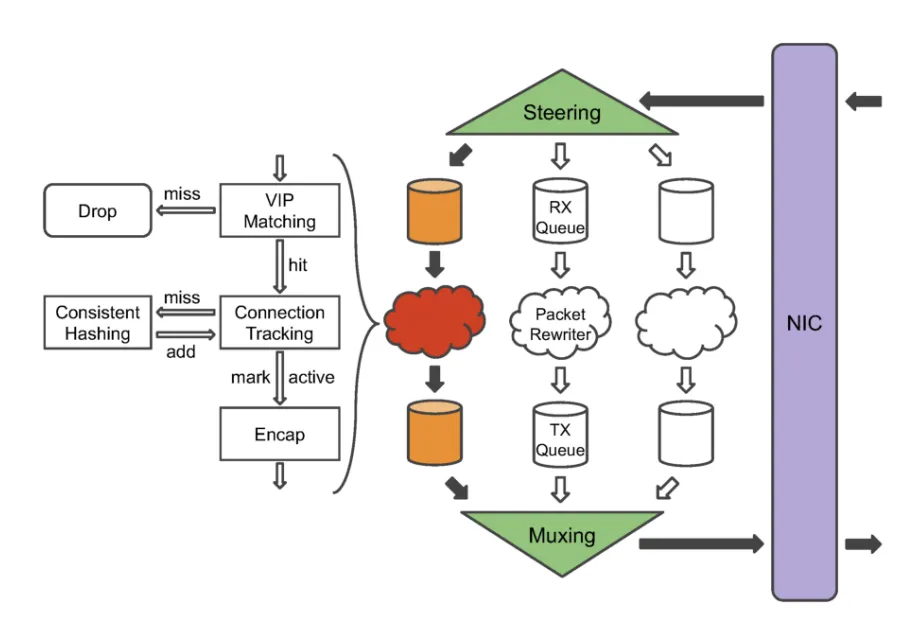
- it has the algorithm to pick the service machine(physical IP)
- packet flow: NIC(network interface card) => steering => rx(receiving) queue => packet rewriter => tx(transmission) queue => muxing => NIC
- A TCP connection is identified by 5-tuple(source IP, source port, destination IP, destination port, and IP protocol)
- steering first calculates the 5-tuple hash and puts the packet in queue based on this hash.
- fallback mechanism if rx queue for the hash fills up(for e.g if there is a flood of packets with same 5-tuple) - packets are put in other receiving queues in a round robin fashion
- packet rewriter -it first matches the VIP in packet with the VIPs the machine is configured to serve, and does early return if no match is found.
- then it recalculates the 5-tuple hash and checks if it’s present in the connection table
- there is a local connection table per packet rewriter thread, keeping track of recent connections via 5-tuple hash to the backend selected. This table ensures packets from same source go to the same destination(assuming it’s still available).
- If an entry is not present in the table(or the mapped backend is no longer healthy), a backend is selected via a modified version of the consistent hashing algorithm and stored in the connection table.
- there are some hardware level optimizations as well with the NIC to bypass linux kernel for high performance.
- Backend selection -
- For connection oriented protocols(like TCP) - stickiness has to be there, all packets must be sent to the same backend.
- A new version of consistent hashing + local connection table(5-tuple to backend) to cache the selection does this effectively.
- why not just connection table?
- as the connection table is local, it goes away with the maglev machine going down(say for rolling deployment)
- if the rx queue for the 5-tuple fills up with flood of packets, ensures we’re usually still selecting the same backend in other packet threads.
- using a centralized connection table(distributed key-val store) won’t be feasible for the scale needed
- why not just consistent hashing?
- connection table is more performant, the backend selection is cached
- only consistent hashing can lead to different selected based on small variances(new server comes up, weights of the server changes etc.), connection table better ensures the stickiness and prevents against such variances
- Monitoring and debugging - there are special packet tracer packets which can be sent with debugging tools. This makes the Maglev machine processing it also send debugging information to a server IP encoded into those special packets.
Consistent hashing with guaranteed even distribution - Algorithm
-
a modified version of consistent hashing called Maglev hashing. Trades off some resilience for even distribution.
-
maglev’s focus is more on even load balancing than minimal backend changes for the input(unlike consistent and rendezvous hashing). As it’s not as relevant for load balancing + the connection tracking table anyway provides a good degree of protection.
- from an experiment outlined in the paper - “Maglev hashing provides almost perfect load balancing no matter what the table size is. When table size is 65537(and number of backends=1000), Karger and Rendezvous require backends to be overprovisioned by 29.7% and 49.5% respectively to accommodate the imbalanced traffic. The numbers drop to 10.3% and 12.3% as the table size grows to 655373. Since there is one lookup table per VIP, the table size must be limited in order to scale the number of VIPs. Thus Karger and Rendezvous are not suitable for Maglev’s load balancing needs.”
- in short - Karger(the original consistent hashing paper) and Rendezvous require a really big lookup table for even distribution. This is really bad for a “load balancer” where the lookup tables has to be maintained per VIP.
- Resilience - normal consistent hashing guarantees that when a backend is removed, only the entries pointing to that backend need to be updated. Maglev doesn’t give this guarantee but is decently resilient to backend changes in practice especially when paired with connection tracking.
-
The key space is broken into a fixed number of slots and nodes are assigned to slots. When nodes change, this assignment is recalculated.
-
Each backend node has a preference list of slots (a permutation array of all slots). This is calculated with help of two hash functions.
# node can be name of node# M(a prime number) is number of slots# returns a permutation of [0, M)def get_preference_permutation(node, M): h1 = hash(node) h2 = hash(node + "salt") # or different hash function offset = h1 % M skip = h2 % (M - 1) + 1 permutation = [(offset + j * skip) % M for j in range(M)] return permutation- We iterate till all slots are assigned. In each iteration, loop over all nodes, and try to assign their next preferred unassigned slot.
# returns the backend assignment for each slotdef populate_lookup_table(backends, M): assignment = [-1] * M assigned_cnt = 0
while assigned_cnt < M: for i, node in enumerate(backends): for preferred_slot in node['permutation']: if assignment[preferred_slot] >= 0: continue assignment[preferred_slot] = i assigned_cnt += 1 return assignment(The code above is a simplified version, we can keep track of which position are we currently pointing to in preferred slot per backend to get rid of the last O(N) factor). So worst case time complexity is $O(M*N)$. We always choose M >>> N, and the average time complexity is $O(MlogM)$.
This guarantees two things -
- even distribution - difference between any node’s assigned slots is less than N/M.
- Low disruption - on average, adding a new node causes reassignment of M/N slots.
Lookup table generation time in maglev -
- tablesize = 65537 => ~2ms (this is the default table size in maglev)
- tablesize = 655373 => ~23ms
Used by
- Cloudflare - flow is from network router => L4 Maglev based load balancers => service’s L7 servers
- SolidCache